엑셀 TEXTBEFORE 함수로 구분자 앞 텍스트 추출하기
IT,PC,모바일,스마트폰 정보와 팁 그리고 제품리뷰와 생활정보

엑셀 TEXTBEFORE 함수로 구분자 앞 텍스트 추출하기
엑셀 작업을 하다 보면 구분자(쉼표, 하이픈, 공백 등) 앞에 있는 특정 텍스트만 필요할 때가 있습니다. 많이 사용하는 방법중에서 엑셀에서 붙여 넣기 할때 텍스트 마법사를 이용을 해서 구분기호를 넣어서 분류 하는 방법인데요. 비슷한 방법으로 함수를 이용을 할수가 있는데요. TEXTBEFORE 함수는 바로 이런 상황에서 강력하게 활용할 수 있는 함수입니다. 이 글에서는 TEXTBEFORE 함수의 사용법과 주요 옵션들을 함께 살펴보겠습니다.
TEXTBEFORE 함수란?
TEXTBEFORE 함수는 텍스트 데이터에서 원하는 구분자 앞의 텍스트만 간편하게 추출할 수 있도록 도와줍니다. 여러 구분자가 있는 경우에는 특정 구분자 앞의 텍스트를 지정해 추출할 수 있어 유용합니다. 예를 들어, “서울-부산-대구”라는 텍스트에서 "서울"과 "부산"까지만 추출하고 싶을 때도 TEXTBEFORE를 이용할 수 있습니다.
함수 구문
TEXTBEFORE 함수의 기본 구문은 다음과 같습니다. 옵션이 여러개 있기는 하지만 기본적인 사용방법은 텍스트 원본데이터와 원본 데이터를 구분할수 있는 구분자를 넣어 주는겁니다. 나머지는 선택 옵션으로 필요에 의해서 사용을 할수가 있습니다.
- text: 텍스트가 포함된 원본 데이터입니다.
- delimiter: 텍스트를 구분하는 기준이 되는 문자(예: 쉼표, 하이픈).
- instance_num (선택): 구분자의 몇 번째 위치를 기준으로 할지 설정할 수 있습니다.
- match_mode (선택): 대소문자 구분 여부. 0은 구분, 1은 무시입니다.
- match_end (선택): 텍스트 끝을 구분자로 처리할지 여부.
- if_not_found (선택): 구분자를 찾지 못했을 때 반환할 값을 지정합니다.
TEXTBEFORE 기본 사용 예제
예를 들어, “홍길동, 대표”라는 텍스트에서 ‘홍길동’ 부분만 추출해보겠습니다. 구분자로 쉼표(,)를 사용하여 함수를 입력합니다. 아래 보시는 것처럼 A1 에 있는 홍길동, 대표 라는 텍스트에서 , 를 분자로 앞에 있는 홍길동만 추출을 하게 됩니다.
이와 같이 TEXTBEFORE 함수는 지정한 구분자 앞의 텍스트를 쉽게 추출해 줍니다.

여러 구분자가 있는 경우
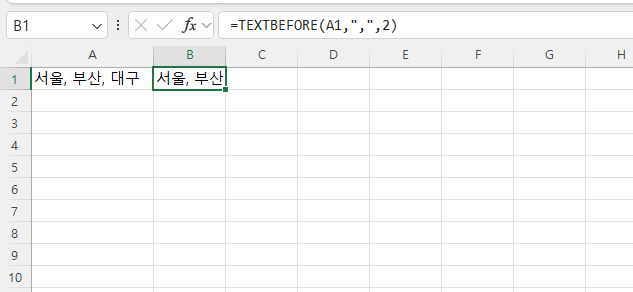
구분자가 여러 번 등장하는 경우 특정 위치의 구분자 앞의 텍스트만 가져올 수도 있습니다. 예를 들어 두 번째 구분자 앞까지의 텍스트를 추출하고 싶다면 instance_num에 2를 입력합니다. 아래 예제에서는 서울, 부산, 대구 라고 되어 있는 A1 셀에서 TEXTBEFORE 함수를 사용해서 선택 옵션인 instance_num 번호를 2를 줘서 두번째 , 를 기준으로 앞에 텍스트인 서울, 부산 을 가져오도록 해보았습니다.
뒤에서부터 텍스트 추출하기
만약에 비슷하게 출력을 하지만 특정 구분자를 뒤에서부터 찾고 싶다면 instance_num에 음수를 사용하면 됩니다. 예를 들어, 마지막 하이픈 앞의 텍스트를 추출하려면 -1을 입력합니다.
대소문자 구분 없이 추출하기
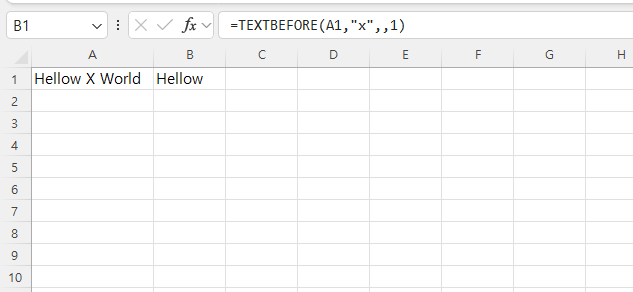
그리고 추출을 할때 대소문자를 구분을 할수도 있지만 부시를 할수도 있습니다. 대소문자를 무시 하고 싶으시다면 아래와 같이 입력을 하시면 대소문자를 무시하여 출력을 할수가 있습니다. 아래 예제에서는 x 와 X 의 구분이 의미가 없어 져서 동일한 결괄를 볼수 있는 예제 입니다. TEXTBEFORE 함수는 기본적으로 대소문자를 구분하지만, match_mode를 사용하면 대소문자 구분을 무시할 수도 있습니다.
이번 포스팅에서는 TEXTBEFORE 함수의 다양한 활용법을 소개해 드렸습니다. 이 함수만 잘 알아두어도 엑셀에서 데이터 관리가 훨씬 수월해질 것입니다. 엑셀 작업 시 구분자 기준으로 데이터를 손쉽게 정리하고 싶다면 TEXTBEFORE 함수를 꼭 활용해 보세요!